搞AI的都知道,大型语言模型(LLM)能力确实强,但部署起来是真费劲——计算量和内存占用都大得吓人。最近谷歌DeepMind放出了个新架构,名叫Mixture-of-Recursions(简称MoR),不少人觉得这玩意儿可能会成为传统Transformer的“终结者”。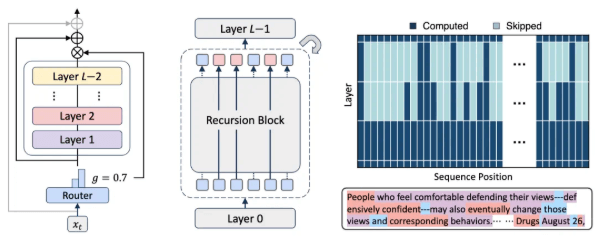
MoR架构介绍
MoR不是凭空造出来的,它是在递归Transformer的基础上做的创新。核心目标就两个:一是让参数能共享,二是实现计算的自适应。
具体来说,它把动态的token级路由整合到了高效的递归Transformer里。简单解释下,就是通过一个轻量级的路由系统,给每个token分配专属的递归深度。打个比方,就像老师给不同学生布置不同难度的作业,让每个token只“思考”必要的层数,不做多余计算。这样一来,计算资源能分配得更合理,处理效率自然就上去了。
实现细节
MoR能提高效率,关键在于它的缓存机制和一系列优化手段:
- 智能缓存:它的缓存机制很灵活,会根据token的递归深度,有选择地缓存和调取相关的键值对。这一招直接减轻了内存带宽的压力,推理吞吐量也跟着提上来了。
- 多重优化:除了缓存,它还搞了参数共享、计算路由、递归级缓存这些操作。这么一套组合拳下来,参数量少了不少,计算开销也降了很多。
实验数据
光说不练假把式,实验结果才是硬道理。在相同的计算预算下,MoR用更少的参数就超过了原始Transformer和递归Transformer。
有个关键数据很亮眼:MoR的参数量减少了将近50%,但在少样本学习的平均准确率上,反而比基线模型表现更好。研究人员分析,这主要是因为它的计算策略够高效,能处理更多的训练token。
而且不管计算预算多少,MoR都比递归基线模型强。特别是当模型规模超过360M时,它不光能追上原始Transformer,在低到中等预算的情况下,还经常能反超。这说明MoR是个可扩展的高效替代方案,用来做大规模预训练和部署挺合适。
总结
MoR架构的出现,算是给大型语言模型的高效化提供了一个新解法,说不定能成为AI研究领域的一个新突破。
对了,想深入研究的可以看论文:alphaxiv.org/abs/2507.10524
相关文章






