今天这篇文章,聊聊过去三年,AI领域的技术逻辑变化趋势。
特别声明:本文关于AI技术演进的顺序并非严格遵循时间节点,但大体的顺序是线性叙事。原因有两方面:1-阅读感受的流畅性;2-技术发展的必然性。
关键时间节点和与之对应的代表性技术/产品顺序,可参考下图:
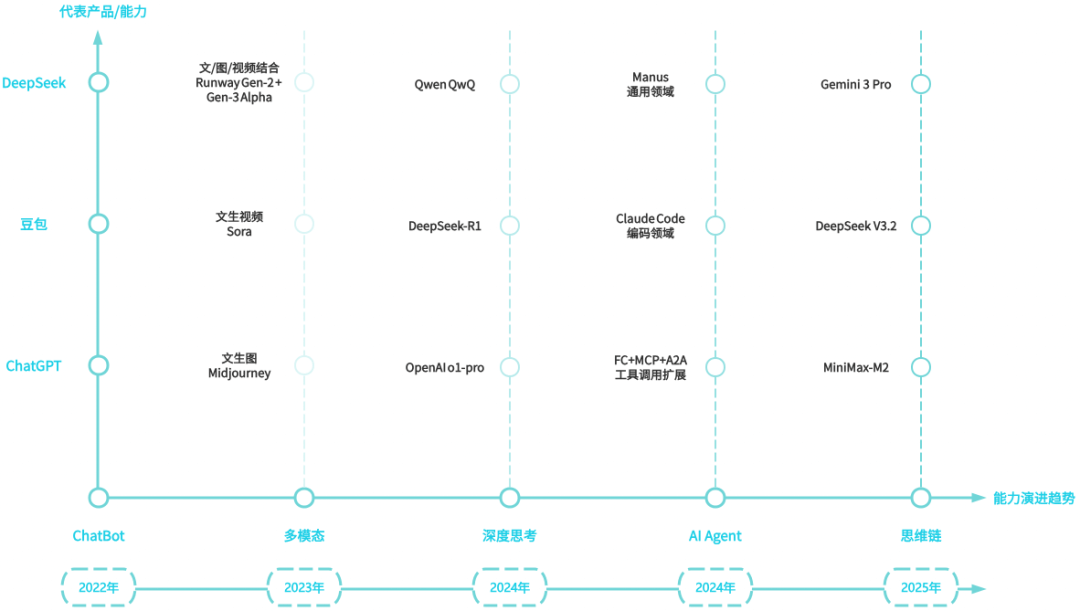
2022年ChatGPT刚出现时,它最令人惊叹的能力是“把话说清楚”。
以前我们在互联网获取信息的方式,基本都是通过浏览器输入自己想要查询的信息,然后搜索引擎通过内容检索,将相关内容以链接的方式展示出来。
这些内容展示的方式、顺序、置信度,对普通人来说其实是不太友好的。因为搜索引擎只是做了内容检索,但结果依然需要用户自己去阅读理解,乃至重新拼装组合,才可能获得相关的结果。
为什么OpenAI的ChatGPT能成为行业发展风向标,原因就在于:用户只需要输入想要查询的信息(提示词),它就能快速展现出逻辑清晰的结果。这意味着我们获取信息的成本大幅度降低,你可以通过ChatBot,“所见即所得”。
随着ChatGPT的爆火,23年上半年,提示词着实火了一阵。但这只是使用方式的问题,这里不过多赘述。
当基于大模型技术的ChatBot可以“把话说清楚”后,业内的关注点又转移到了AI的推理能力方面。
即大模型在给出结果时,要不要展示它背后的推理过程,展示多少合适,以及如何控制推理成本(Token消耗量)。这个阶段有一个标志性的术语,叫做CoT(Chain-of-Thought)。
CoT(Chain-of-Thought):一种让模型在回答问题之前先进行逐步推理的技术,它的核心思路是将解题过程拆成若干有序的思考步骤,而不是直接给出最终答案。
目前的大语言模型,本质上是一种概率预测机器。用户输入同样的信息(提示词),大模型会给出不同的答案,这就是所谓的信息幻觉问题。从技术的角度来说,针对同一个或同一组Prompt,大模型的结果不具备幂等性。
为了缓解大模型的信息幻觉问题,RAG技术应运而生。
RAG(Retrieval-Augmented Generation)的意思是检索增强生成,即结合向量数据库中与用户问题高度相关的信息以及Prompt一起投喂给大模型,再生成结果。
将RAG解决信息幻觉的过程进行拆解,可以分为三个步骤:理解-检索-生成。
- 理解:拆解知识点,充分理解用户的需求;
- 检索:找到最合适的信息,然后进行搜索排序优化,并将搜索返回的异构信息统一表示,再送给大模型;
- 生成:综合不同来源信息做出判断,并基于大模型的逻辑推理能力,解决信息冲突等问题,最后生成准确率高、时效性好的答案。
信息幻觉问题得到缓解后,为了在成本和效率方面做出平衡,就有了低冗长(Verbosity: low)的CoT技术。
所谓的低冗长(Verbosity: low)CoT技术,简单来说就是大模型在给出结果时,只保留关键推理环节,省去不必要的解释和细节,使得思考链简洁明了。它的实现方式大致有如下几个步骤:
- 明确问题:一句话概括要解决的任务。
- 列出关键步骤:只写出每一步的核心操作或公式,不展开冗长的背景说明。
- 得出结论:在完成关键步骤后直接给出答案。
这种方式的好处在于:既能让模型保持逻辑连贯,又避免了冗余信息,适合需要快速、精准输出的场景。
解决了信息幻觉和推理成本问题后,AI Agent和MCP等工具随之登上了舞台。
很多时候技术发展的驱动力其实是源于人的欲望:有了好的,就想要更好。大家对AI的关注点,从一开始的“把话说清楚”,到大模型的推理能力,再到动手能力。即不仅要能说会想,更要会做事。
这个时候,单轮对话式的“能说会想”能力就有点不够用了,大模型需要在一大串的调用逻辑中,去回忆一下自己刚才“都做了哪些思考”。此时,一位靓仔出现了,它就是扩展思考(Extended Thinking)。
Extended Thinkin亦称之为Interleaved Thinking(交叉思考),它允许模型在回答问题前先有一段内部推理,再把必要的信息暴露出来。最早由Anthropic在在其官方研究博客中提出,并随Claude 3.7 Sonnet于2025年2月24日正式发布。
为什么这里要提到Extended Thinkin?原因在于:做事需要严谨的步骤和可临时调整的能力。
低冗长(Verbosity: low)CoT技术解决了推理成本问题,扩展思考(Extended Thinkin)解决了翻阅记忆(上下文记忆)难题。只有具备这两项能力,AI在执行任务时,才能完成工具调用和调整执行步骤。
当然,工具可能来自不同企业和个人,因此MCP协议成为了事实上的AI通信标准。完成复杂任务可能需要多个模型来承担不同的细分任务,MoE(Mixture‑of‑Experts:专家混合)模型架构就此出现。
继Extended Thinkin之后,最近业内关注点又转移到了“Thinking in Tool Use”。简单来说,就是让模型一边进行推理,一遍进行工具调用以完成任务。
MiniMax在今年10月发布新模型M2时,就把Interleaved Thinking作为设计重点之一。在它之后,Gemini 3 Pro、DeepSeek V3.2等新模型相继发布,都宣布支持“推理思考+工具调用”的能力。
你可以这样理解:Agent要想完成复杂任务,就必须不断重复以下步骤:
- 规划下一步行动;
- 根据工具返回的结果,调整后续策略;
- 记住已经尝试过的方案,避免重复犯错;
- 在多轮交互中保持目标不偏离,避免状态漂移。
再专业一点来说,必须让模型在显式推理(reasoning)与工具调用(tool use)之间交替进行,并且在多轮交互中,持续保留和传递之前每一步的推理状态。
Interleaved Thinking机制的另一重作用就是将上述步骤变成模型的默认行为,即“制定计划-任务执行-结果反思”。这种机制化的能力,是更容易被框架理解和承载的格式,更便于让模型以API的形式在工具调用之间保留自己的假设、约束、中间结论和纠错记录。
截至目前,这种机制已经成为AI完成任务的一种共识:只有将Interleaved Thinking机制融入真实的工作流程,大模型才有可能完成复杂的任务。
在我看来,这种在长链路复杂任务中能显著提升规划能力,具备自我修正能力并提升结果可靠性的机制,是接下来AI真正从Infra层走向应用层的核心能力。
从更高维的角度看,这种机制无论对模型、Agent,还是对开发者和生态来说,都具备重要的意义。
对模型来说,它提供了更先进可靠的机制,模型可以在思考推理和工具调用的过程中进行持续不断的纠偏。
对Agent来说,它可以很好的提升可靠性,Agent可以将预定计划、错误日志以及过程中产生的结果当作参考。
对开发者来说,它能带来更好的过程可观测性,开发者可以通过推理过程、错误日志进行问题定位和修复验证。
对AI生态来说,它推动了接口和通信协议的标准化,以后不必再为不同的模型和平台进行适配,开发者完全可以通过统一的协议规范进行开发调试和部署。
最后做一个总结:Interleaved Thinking机制增加了AI能真正完成任务的可能性,可以显著提升Agent在复杂任务中的规划能力与稳定性,它使得长链路任务具备可调试性,避免了状态漂移,最终推动模型“推理思考+工具调用”的过程进入标准化模式。
一句话概括:模型的工作机制,会从Workflow+Agent模式演进到Self Agent模式。
相关文章






