智谱这边正式推出了视觉推理模型GLM-4.5V,而且还开源了!这可是全球100B级里效果最顶的开源视觉推理模型,也是智谱在通用人工智能(AGI)这条路上往前迈的一大步。现在,这模型已经在魔搭社区和Hugging Face同步开放了,总参数有106B,激活参数是12B,不得不说,多模态推理技术这是要进入新阶段啦。
模型的核心优势和性能到底怎么样
GLM-4.5V是在智谱新一代旗舰文本基座模型GLM-4.5-Air的基础上开发的,跟GLM-4.1V-Thinking的技术路线是一脉相承的。在41个公开的视觉多模态榜单里,它的综合性能在同级别开源模型中是最厉害的(也就是常说的SOTA),像图像、视频、文档理解、GUI Agent这些任务,它都能搞定。
具体来说,通过高效的混合训练,GLM-4.5V实现了全场景的视觉推理,比如:
- 图像推理、视频理解、GUI任务处理这些都不在话下;
- 复杂的图表和长文档,它也能解析明白;
- 还有精准的Grounding(视觉定位)能力。
其实最值得一提的是,这模型新增加了“思考模式”开关,大家可以根据自己的需求,选快速响应还是深度推理,这样就能灵活平衡效率和效果啦。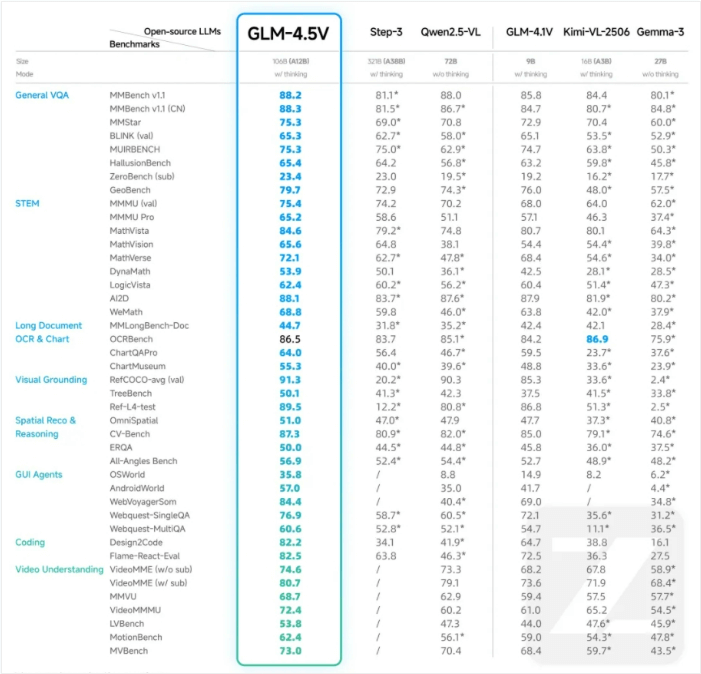
和同类模型比,优势在哪呢
在不少基准测试里,GLM-4.5V的表现都很突出:
- 通用视觉问答(VQA):在MMBench v.1里拿了88.2分,比Qwen2.5-VL(88.0分)这些同类模型还高一点;
- STEM领域:MMMU(val)测试得了75.4分,MathVista达到84.6分,看来它的逻辑和数学推理能力是真不弱;
- 长文档与图表处理:MMLongBench-Doc得44.7分,ChartQAPro达64.0分,比多数开源模型都强不少;
- 视频理解:VideoMME(w/ sub)测试得80.7分,在同类模型里也是领先的。
有啥实用工具和资源支持呢
为了方便开发者体验,智谱清言还同步开源了一款桌面助手应用,能实时截屏、录屏获取屏幕信息,靠着GLM-4.5V来完成代码辅助、视频内容分析、游戏解答、文档解读这些任务,简直就是大家工作和娱乐时的“可视化伙伴”。
不过呢,还有个好消息,GLM-4.5V的API已经在智谱开放平台(BigModel.cn)上线了,新老用户都能领到2000万Tokens的免费资源包。而且它的API调用价格也挺实惠,输入低至2元/M tokens、输出6元/M tokens,响应速度能达到60-80tokens/s,在保证高精度的同时,推理速度和部署成本也兼顾到了,给企业和开发者提供了性价比很高的多模态AI解决方案。
技术细节和怎么获取呢
GLM-4.5V由视觉编码器、MLP适配器和语言解码器三部分组成,支持64K多模态长上下文以及图像、视频输入。技术方面,它通过三维卷积提升了视频处理效率,用双三次插值机制增强了对高分辨率及极端宽高比图像的处理能力,还引入了三维旋转位置编码(3D-RoPE)来强化多模态信息的三维空间关系感知与推理能力。
开发者想获取这模型,可以去这些平台:
相关文章






